How to Choose the Right Data Annotation Approach for AI/ML Development?
How to Choose the Right Data Annotation Approach for AI/ML Development?
- Last Updated: February 13, 2026
Brown Walsh
- Last Updated: February 13, 2026
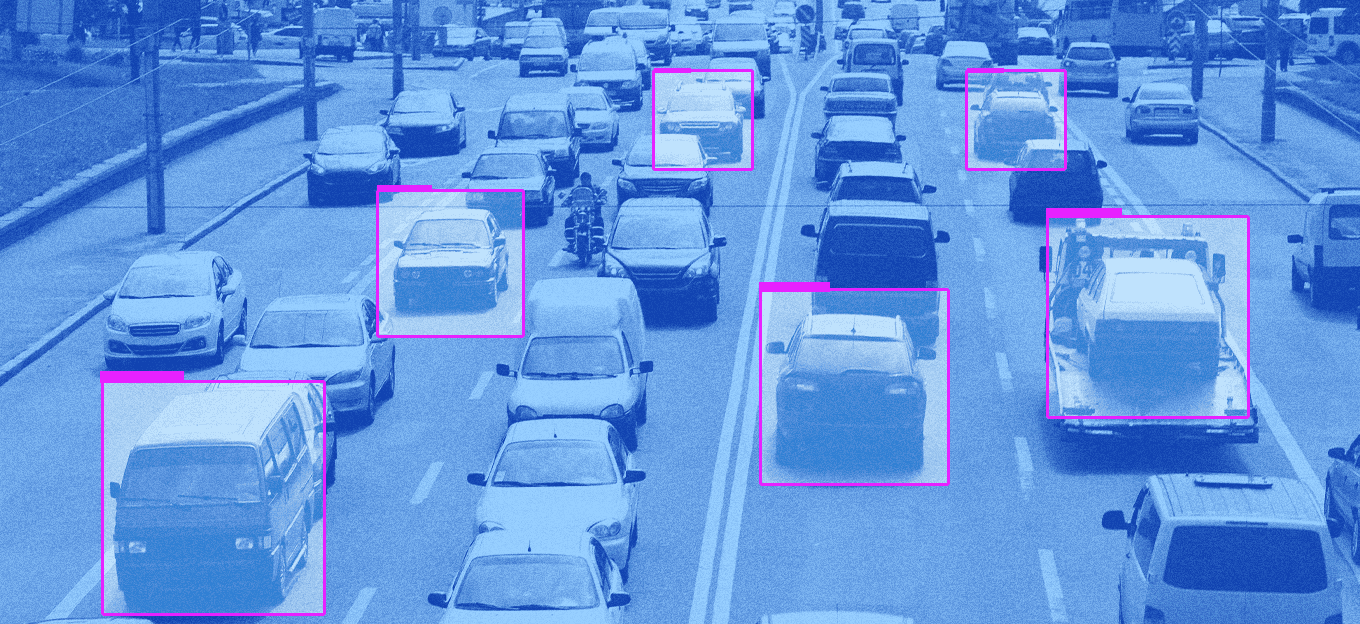
How do you accelerate AI development without compromising data quality, compliance, or cost efficiency?
For most organizations, the answer lies in selecting the right data annotation approach—automated, manual, or human-in-the-loop. While automated annotation delivers the speed required for large-scale datasets, it struggles with nuanced or ambiguous cases; manual annotation offers the precision needed but lacks efficiency at scale. A hybrid model balances both—using automation for throughput and human expertise for edge-case resolution.
This blog breaks down the benefits and limitations of these approaches and explains how to choose the right annotation method with use cases.
Automated Data Annotation: Maximizing Speed and Scalability
Benefits of Annotation Automation:
- Speed & Scalability: Automated data annotation systems are designed to efficiently process and label large datasets, making them ideal for businesses that need to scale. For example, one enterprise deployment reported a 20% uplift in operational efficiency after adopting automated annotation for large-scale data processing, reinforcing its value in speed-centric workflows.
- Long-Term Cost-Effectiveness: Automation offers significant long-term cost savings by reducing the need for additional labor and streamlining operations, helping businesses eliminate ongoing operational costs.
- Standardization: Automation ensures consistent labeling across large datasets, particularly for repetitive tasks. By applying the same rules uniformly, automated systems standardize output, eliminating human error.
Limitations of Annotation Automation:
- Low Accuracy: Automated systems excel at rule-based tasks but fall short when dealing with complex, ambiguous, or edge cases.
- Initial Setup Investment: Deploying automated annotation requires an upfront investment in software, infrastructure, and training, which can be a barrier, especially for smaller businesses or those with limited technical expertise.
Manual Data Annotation: Ensuring Precision and Compliance
Benefits of Manual Annotation:
- Enhanced Precision: Manual data annotation is ideal for tasks that require human judgment and contextual understanding. Domain experts interpret nuanced, ambiguous data and resolve edge cases that automated systems often miss. For example, A recent case study demonstrated that manual annotation contributed to a 25% uplift in model accuracy by addressing complex edge cases.
- Flexibility and Customization: Manual annotation involves tailoring labeling guidelines to meet specific project requirements and adapting to evolving project needs.
- Compliance and Ethical Integrity: When handling sensitive data, such as in medical or financial domains, manual annotation ensures confidentiality and compliance with regulations like the Health Insurance Portability and Accountability Act (HIPAA) and the General Data Protection Regulation (GDPR).
Limitations of Manual Annotation:
- Slow and Labor-Intensive: Manual annotation requires significant time and effort, especially when working with large datasets. Due to limited scalability, project timelines can be delayed.
- High Infrastructure Costs: With increasing data volumes, additional resources are required, leading to higher annotation overhead.
Human-in-the-Loop: Merging Automation with Human Oversight
The hybrid approach combines the automation-driven speed and scalability with the precision of manual annotation, addressing the shortcomings of both automated and manual methods and offering a more balanced, efficient way to annotate large datasets.
How to Choose the Right Data Annotation Approach: Automated, Manual, or Human-in-the-Loop?
- Autonomous Vehicles: While automation can efficiently pre-label large volumes of training data by identifying vehicles, pedestrians, and traffic signals, the outputs require human review for edge cases involving occlusions, unusual road objects, erratic pedestrian behavior, or extreme weather, where automated systems often struggle to interpret context correctly.
- Medical Imaging: While automated models can segment standard anatomical structures at scale, domain-specific annotators are needed to refine annotations in cases involving low contrast, subtle abnormalities, overlapping tissues, or early-stage disease indicators that demand clinical judgment.
- Predictive Maintenance (Industrial IoT): Automation rapidly processes continuous sensor streams, vibration signals, and equipment logs, while domain experts validate anomalies, rare failure patterns, and context-driven variations that automated systems may misinterpret without operational insight.
- Smart Surveillance & Security: While automated detection handles routine object identification and movement tracking across video footage, manual validation is essential when visibility drops, motion becomes rapid or erratic, thermal signatures fluctuate, or overlapping subjects introduce ambiguity.
- Finance & Risk Analysis: Automation can classify large volumes of financial documents and efficiently extract structured data, yet domain-specific annotators must evaluate ambiguous transaction patterns, interpret risk disclosures, and assess potential fraud indicators, where contextual understanding is critical.
The Strategic Imperative
While in-house teams often face challenges—from limited domain expertise and inconsistent labeling quality to bottlenecks in scaling annotation pipelines as data volumes grow—outsourcing data annotation services addresses these constraints by delivering structured workflows, quality assurance, specialized domain expertise, and scalable infrastructure. This approach accelerates data readiness, reduces operational overhead, and enables in-house teams to focus on model architecture, experimentation, and deployment.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

IoT Is Finally Delivering
Related Articles


Related Solutions

Smart Community Management for HOAs
AI-powered community monitoring with real-time visibility into entrances, parking, and shared spaces.
AI-powered community monitoring with real-time visibility into entrances, parking, and shared spaces.
Iveda
Iveda

Construction Site Safety Monitoring
AI-powered wearables for real-time PPE compliance monitoring, hazard detection, and incident documentation.
AI-powered wearables for real-time PPE compliance monitoring, hazard detection, and incident documentation.
Iveda
Iveda

Workers' Compensation Fraud Prevention
Quickly verify claims, reduce investigation time, and protect your bottom line with AI-powered video surveillance and analytics.
Quickly verify claims, reduce investigation time, and protect your bottom line with AI-powered video surveillance and analytics.
Iveda
Iveda
Related Solutions
Buildings & Facilities
Smart Community Management for HOAs
AI-powered community monitoring with real-time visibility into entrances, parking, and shared spaces.
Iveda
Construction
Construction Site Safety Monitoring
AI-powered wearables for real-time PPE compliance monitoring, hazard detection, and incident documentation.
Iveda
Construction
Workers' Compensation Fraud Prevention
Quickly verify claims, reduce investigation time, and protect your bottom line with AI-powered video surveillance and analytics.
Iveda