RAG vs. Fine-Tuning Now a Critical Decision for Companies
RAG vs. Fine-Tuning Now a Critical Decision for Companies
- Last Updated: June 15, 2026
Suman Debnath
- Last Updated: June 15, 2026
Many companies face a crucial architectural decision that directly impacts cost, accuracy, scalability, and operational risk. The question is whether they should use retrieval-augmented generation (RAG), fine-tuning, or a combination of both. Those who make the right decision often find an easier path to success. On the other hand, those who get it wrong typically end up with brittle systems, runaway costs, and outputs they can’t trust.
The decision is challenging since each approach has benefits and is widely used. According to Stanford HAI's AI Index Report 2025, 78% of organizations now use artificial intelligence (AI) in at least one business function, up from 55% the prior year. Yet McKinsey's State of AI 2025 reports that fewer than 15% of organizations have scaled generative AI beyond pilots.
The importance of this decision is easily spotted in the Internet of Things (IoT) and edge environments. Edge devices have limited compute and memory, as well as intermittent connectivity, so they favor fine-tuned models for on-device inference. Operational knowledge favors RAG because it needs to propagate quickly across fleets. It includes everything from sensor configurations to firmware indicators, threat signatures, and regulatory rules.
The decision between RAG and fine-tuning shows up early, even in pilots. Only a small percentage of companies are fully scaled, but nearly 48% are running pilots, and many more are experimenting with or evaluating GenAI. During those pilot stages, teams inevitably hit the question: “Do we connect this to the company’s data (RAG) or train the model (fine-tune)?”
Deciding Between RAG and Fine-Tuning
It’s vital to use specific characteristics when choosing between RAG and fine-tuning. At a fundamental level, RAG stores knowledge externally, while fine-tuning embeds knowledge into the model itself. This seemingly simple architectural choice has far-reaching consequences across five dimensions:
- Information accuracy. RAG systems pull from up-to-date documents at query time, making them ideal for environments where information changes frequently. Fine-tuned models produce static snapshots. Once trained, they don’t know anything new unless the company retrains them.
- Cost structure. RAG typically has lower upfront costs but requires ongoing investment in infrastructure. Fine-tuning entails a higher initial investment in data preparation and training, but when used at scale, it can reduce per-query costs over time. Fine-tuning generally becomes more cost-effective only at very large scale and in environments where knowledge changes infrequently.
- Control and governance. With RAG, responses can be traced back to source documents, providing greater transparency. Fine-tuned models are less transparent because it is harder to pinpoint the source for a specific answer.
- Performance/latency. Fine-tuned models can be faster and more streamlined because they don’t rely on external retrieval steps. RAG introduces additional latency due to search and ranking processes.
- Risk management. Using poor-quality or biased data for fine-tuning can permanently encode issues into the model's weight. RAG is not immune to bad data, but it allows companies to update or remove problematic documents without retraining.
RAG excels when knowledge changes frequently. It is also highly effective when citations or traceability are needed and when data volumes are large and dynamic. In contrast, fine-tuning delivers greater consistency in behavior and tone. It excels when domain knowledge is stable and tasks are repetitive and well-defined (see Table 1).
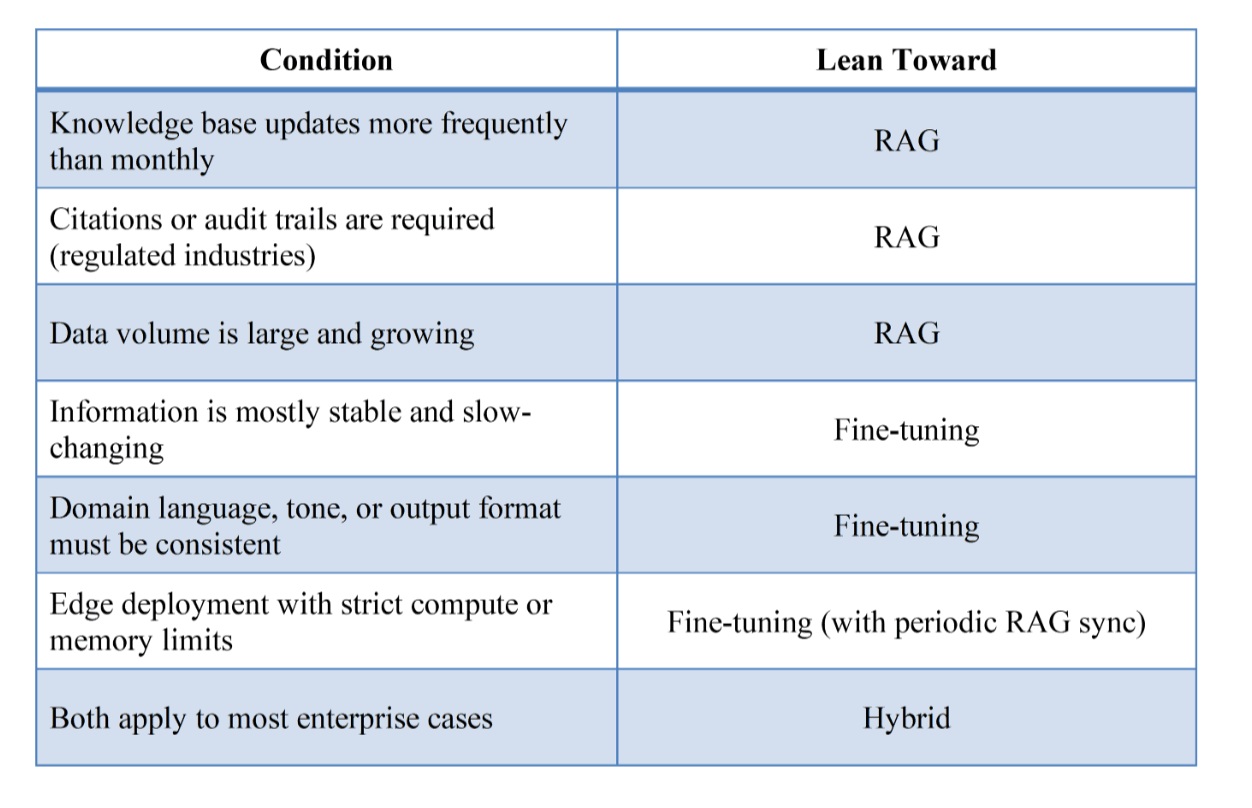
Table 1: RAG versus Fine-Tuning Decision Framework
Why RAG is Gaining Popularity
Several benefits of RAG make it popular, including its accuracy, low cost, and practicality for real-world business use, making it the default starting point for many organizations building AI. NatWest, a large UK bank, chose RAG when it launched an upgrade of its virtual assistant Cora.
Now, when a customer asks a question, the system uses RAG to retrieve relevant banking documents, policies, and frequently asked questions (FAQs). It then feeds that information into the AI system to generate a customized, more context-aware answer. Officials at NatWest state the RAG-powered AI tool has brought customer service to new levels, improved customer satisfaction, and reduced call center volume.
Another example is Microsoft. It uses RAG inside its Azure AI Search and Copilot ecosystem to power internal knowledge assistants and customer-facing tools. The system searches a variety of resources, including internal documents, knowledge bases, and more. It then retrieves the most relevant content and creates a customized response.
RAG is also gaining popularity due to exciting innovations. A particularly important one is multimodal RAG using vision-language embeddings such as ColPali. Traditional RAG systems lose significant information from charts, tables, and visually structured documents because they convert documents to text before embedding. ColPali processes document images directly, preserving visual layout and structural information.
In a recent project, integrating ColPali with the CrewAI agentic framework materially improved retrieval over text-only baselines for documents containing diagrams, schematics, and tables. For IoT and industrial settings where technical documentation and equipment manuals are the primary knowledge sources, multimodal RAG is increasingly the right starting point.
Using RAG and Fine-Tuning Together
The use of RAG ensures that a model has access to up-to-date, domain-specific information at query time. Adding fine-tuning to the model mix ensures it communicates in the way the company wants. It’s the best of both worlds.
Determining whether to use RAG, fine-tuning, or a combination is critical for the long-term performance and trustworthiness of a company’s AI systems. It also dramatically impacts cost. Choosing incorrectly can lock a company into an architecture that is too complex and expensive to scale efficiently, resulting in a system that cannot adapt to today’s rapidly changing marketplace.
Companies that take the time to investigate both approaches, weigh their advantages and disadvantages, stay aware of new advances such as multimodal/vision-based RAG, and, when appropriate, consider a hybrid approach can experience a wide range of benefits. Those benefits include improved decision-making, smoother, more efficient operations, and enhanced customer experience.
Suman Debnath is a recognized leader in generative AI, ML infrastructure, and distributed computing. He currently serves as Principal Developer Advocate and Head of Developer Relations at Anyscale, the company behind the open-source Ray framework used by OpenAI, Uber, Netflix, and Spotify. Previously, as Principal Developer Advocate for AI/ML at AWS, Debnath authored the “zero-setup RAG” architecture on Amazon Bedrock that has been adopted by more than 1,000 enterprise customers worldwide. He is a member of the Forbes Technology Council, has authored six peer-reviewed papers at IJCNLP-AACL 2025 and IEEE, and has delivered more than 100 presentations at major AI/ML conferences. His courses on freeCodeCamp and Analytics Vidhya have reached audiences exceeding 15 million practitioners across two of the world's largest developer learning platforms. Connect with Suman on LinkedIn.
The Most Comprehensive IoT Newsletter for Enterprises
Showcasing the highest-quality content, resources, news, and insights from the world of the Internet of Things. Subscribe to remain informed and up-to-date.
New Podcast Episode

IoT Is Finally Delivering
Related Articles


Related Solutions

Smart Community Management for HOAs
AI-powered community monitoring with real-time visibility into entrances, parking, and shared spaces.
AI-powered community monitoring with real-time visibility into entrances, parking, and shared spaces.
Iveda
Iveda

Construction Site Safety Monitoring
AI-powered wearables for real-time PPE compliance monitoring, hazard detection, and incident documentation.
AI-powered wearables for real-time PPE compliance monitoring, hazard detection, and incident documentation.
Iveda
Iveda

Workers' Compensation Fraud Prevention
Quickly verify claims, reduce investigation time, and protect your bottom line with AI-powered video surveillance and analytics.
Quickly verify claims, reduce investigation time, and protect your bottom line with AI-powered video surveillance and analytics.
Iveda
Iveda
Related Solutions
Buildings & Facilities
Smart Community Management for HOAs
AI-powered community monitoring with real-time visibility into entrances, parking, and shared spaces.
Iveda
Construction
Construction Site Safety Monitoring
AI-powered wearables for real-time PPE compliance monitoring, hazard detection, and incident documentation.
Iveda
Construction
Workers' Compensation Fraud Prevention
Quickly verify claims, reduce investigation time, and protect your bottom line with AI-powered video surveillance and analytics.
Iveda